在人工智能与音乐技术的交汇处,CLaMP 3横空出世,为音乐信息检索领域带来了革命性的突破。由清华大学人工智能学院的朱文武教授团队开发的CLaMP 3,是一款多模态、多语言的音乐信息检索框架,旨在通过对比学习技术,实现跨模态音乐检索、零样本音乐分类和音乐推荐等功能。
CLaMP 3是什么?
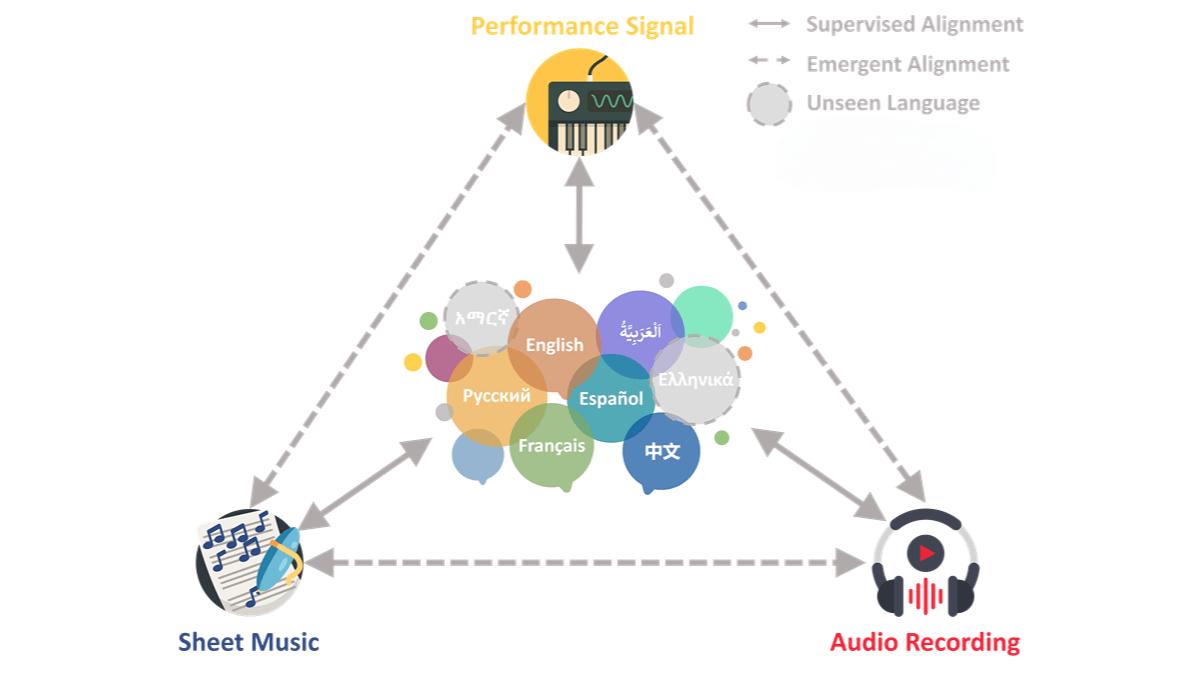
CLaMP 3是一款基于对比学习的多模态音乐信息检索框架,它能够将乐谱、音频和表演信号与多语言文本描述对齐到一个共享的表示空间中。这一框架支持27种语言,并可泛化到100种语言,适用于多种跨模态检索任务,包括文本到音乐检索、图像到音乐检索、零样本音乐分类和音乐语义相似性评估。
CLaMP 3的主要功能
-
跨模态音乐检索
-
文本到音乐检索:支持100种语言的文本描述,能够检索出语义匹配的音乐。
-
图像到音乐检索:通过图像生成的描述(如BLIP模型生成的caption),检索与之匹配的音乐。
-
跨模态音乐检索:在不同音乐表示形式(如乐谱、MIDI、音频)之间进行检索,例如用音频检索乐谱或用乐谱检索音频。
-
-
零样本音乐分类 无需标注数据,基于语义相似性将音乐分类到特定类别(如风格、情绪等)。
-
音乐推荐 基于语义相似性进行音乐推荐,支持同一模态内的推荐(如音频到音频)。
CLaMP 3的技术原理
-
多模态数据对齐 CLaMP 3通过对比学习,将不同模态的音乐数据(如乐谱、MIDI、音频)和多语言文本统一到一个共享的语义空间。模型学习将不同模态的数据映射到相似的向量表示,从而实现跨模态检索。
-
对比学习框架 采用对比学习(如CLIP的变体)训练模型。模型通过正样本对(如音乐与对应文本)和负样本对(随机配对的样本)学习区分语义相关和不相关的数据,优化表示空间。
-
多语言支持 基于XLM-R(一种多语言预训练模型)实现多语言文本嵌入,支持27种语言的训练,并泛化到100种语言。
-
大规模数据集训练 模型在大规模数据集(如M4-RAG)上进行训练,包含231万对高质量的音乐-文本对,覆盖27种语言和194个国家。
-
特征提取与表示
-
乐谱:使用Interleaved ABC符号。
-
MIDI:转换为MIDI文本格式(MTF)。
-
音频:提取MERT特征。
-
CLaMP 3的应用场景
-
音乐推荐 根据文本描述或音乐片段,推荐语义相似的音乐,支持个性化推荐。
-
音乐创作辅助 通过文本生成匹配的音乐,帮助创作者找到灵感或调整音乐风格。
-
音乐教育 检索相关音频、乐谱或教学资源,支持多语言学习。
-
音乐分类与分析 零样本分类音乐风格、情绪等,评估音乐语义相似性。
-
多媒体创作 为视频或图像匹配合适的音乐,提升内容制作效率。
CLaMP 3的项目资源
-
GitHub仓库:https://github.com/sanderwood/clamp3
-
HuggingFace模型库:https://huggingface.co/sander-wood/clamp3
-
arXiv技术论文:https://arxiv.org/pdf/2502.10362
结语
CLaMP 3的推出,标志着音乐信息检索技术迈向了一个新的高度。无论是音乐推荐、创作辅助,还是教育和多媒体创作,CLaMP 3都展现出了强大的应用潜力。对于开发者、音乐爱好者以及内容创作者来说,CLaMP 3无疑是一个值得探索的宝藏工具。立即访问项目官网,体验CLaMP 3的强大功能吧!