在人工智能快速发展的今天,语音技术正在改变我们的生活方式。无论是智能客服、智能家居,还是教育工具,语音理解模型都发挥着重要作用。今天,我们将深入解析由西北工业大学推出的开源语音理解模型——OSUM,探索它如何助力语音识别、情感分析等多任务场景。
一、OSUM是什么?
-
OSUM(Open Speech Understanding Model)是由西北工业大学计算机学院音频、语音与语言处理研究组开发的开源语音理解模型。
-
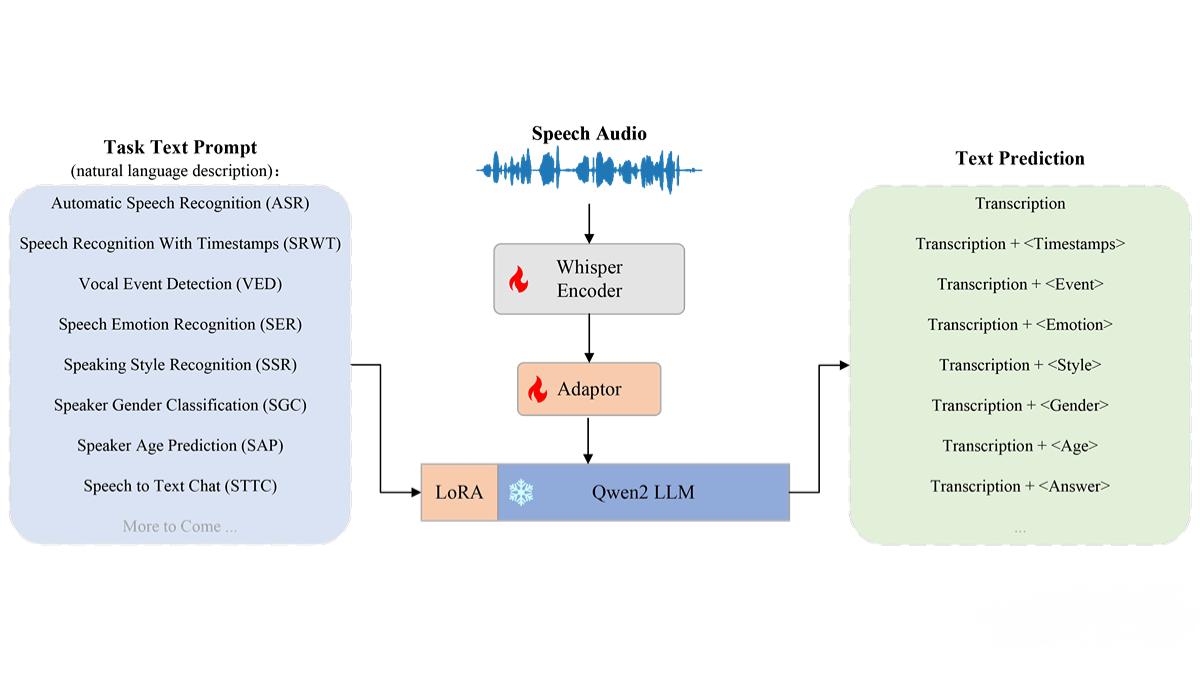
结合Whisper编码器和Qwen2 LLM,支持语音识别(ASR)、语音情感识别(SER)、说话者性别分类(SGC)等多种任务。
-
基于“ASR+X”多任务训练策略,实现高效稳定的训练。
二、OSUM的主要功能
-
语音识别:支持多种语言和方言,准确将语音转换为文本。
-
带时间戳的语音识别:输出每个单词或短语的起止时间,便于后续处理。
-
语音事件检测:识别笑声、咳嗽、背景噪音等特定事件。
-
语音情感识别:分析高兴、悲伤、愤怒等情感状态。
-
说话风格识别:区分新闻播报、客服对话、日常口语等风格。
-
说话者性别和年龄分类:判断性别和年龄范围。
-
语音转文本聊天:将语音输入转化为自然语言回复,适用于对话系统。
三、OSUM的技术原理
-
Speech Encoder:采用Whisper-Medium模型(769M参数),负责将语音信号编码为特征向量。
-
Adaptor:包含3层卷积和4层Transformer,用于适配语音特征与语言模型的输入。
-
LLM(语言模型):基于Qwen2-7B-Instruct,通过LoRA微调适应多任务需求。
-
多任务训练策略:
-
ASR+X训练范式:同时训练语音识别和附加任务,提升泛化能力。
-
自然语言Prompt:通过不同提示引导模型执行任务。
-
数据处理与训练:约5万小时的多样化语音数据,分为两阶段训练。
-
四、OSUM的应用场景
-
智能客服:结合语音识别和情感分析,提供个性化服务。
-
智能家居:识别语音指令和背景事件,优化交互体验。
-
教育工具:分析学生语音,提供学习反馈。
-
心理健康监测:检测语音情绪变化,辅助评估。
-
多媒体内容创作:自动生成字幕和标签,辅助视频编辑。
五、如何获取和使用OSUM?
-
GitHub仓库:https://github.com/ASLP-lab/OSUM