多模态AI的定义
多模态AI是一种创新的人工智能技术,它超越了传统AI只能处理单一类型数据(如仅文本或仅图像)的局限。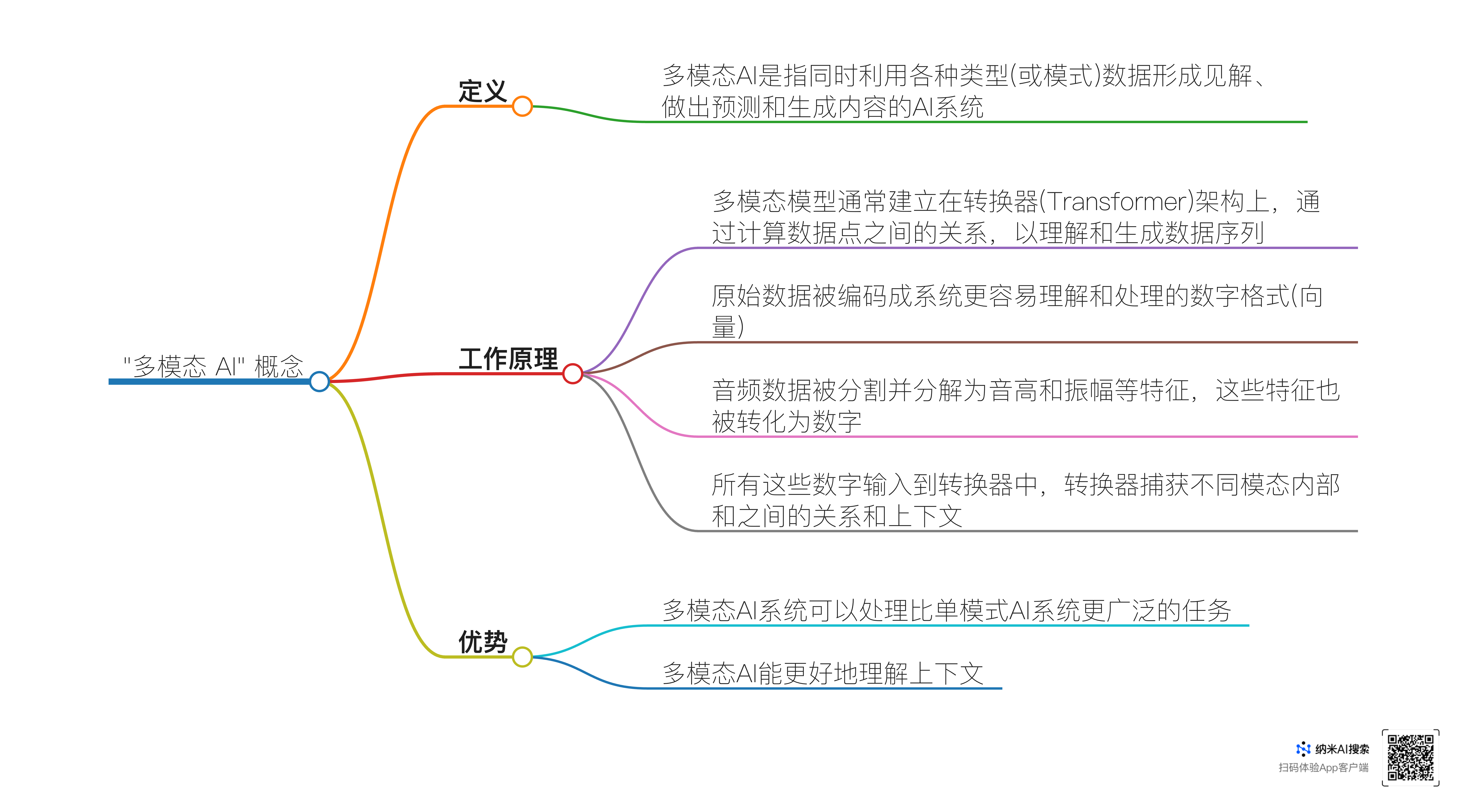
- 多模态数据处理能力
- 多模态AI能够同时处理多种类型的数据,这些数据类型包括文本、图像、视频、音频以及语音等。例如,Gemini是多模态大模型,可以同时识别和理解文本、图像、音频、视频和代码五种信息。它通过计算数据点之间的关系来理解和生成数据序列,对于各种类型的数据采用相似的处理逻辑。在处理文本数据时会分析字、词之间的上下文关系;对于图像,能够识别其中的物体、场景等元素;对音频则会解析像音高、振幅等特征。以一张含有食物的照片为例,如果是多模态AI系统,可以直接基于照片中的食物视觉信息生成对应的食谱,而传统的单模态AI则往往难以做到这种跨类型数据的任务操作。
- 在模型构建上,多模态模型通常以转换器(Transformer)架构为基础。这种架构使得模型能够有效地捕捉不同模态内部和不同模态之间的关系与上下文信息。例如,模型在处理“鸭子”这个概念时,不仅能关联到“鸭子”这个单词,还能对应其外观形象以及嘎嘎叫的声音等多方面的信息,从而从更广泛的概念层面去理解鸭子。
- 多模态AI往往需要经过一个将原始数据编码成数字格式(向量)的嵌入(Embedding)过程,使得系统更容易理解和处理。例如音频数据经过嵌入过程后,原本复杂的声音信号被分割并转化为向量表示,便于和其他模态数据一同进行分析处理。在有些情况下,还有早期融合(EarlyFusion)和后期融合(LateFusion)等数据融合方式,早期融合将来自每种模态的原始数据组合、对齐和处理,使它们具有相同(或相似)的数学表示,但这种方式实现难度较高;后期融合则是在每种类型的数据分别进行分析和编码之后再合并来自多个模态的信息,这是目前许多多模态系统采用的方式。
- 与单模态AI的对比
- 单模态AI模型就只能局限于一种类型的数据输入和特定数据模态的输出。例如,大型语言模型(LLM)大多数情况下只能处理文本数据,如GPT - 3.5主要支持文本输入和输出,属于典型的单模态模型;而卷积神经网络(CNN)主要是专门为处理图像数据而构建。多模态AI模型的能力就更加全面,处理的任务范围更广。例如,多模态的聊天机器人就能比纯文本的聊天机器人更有效地响应用户需求,提供更加丰富的信息,用户可以输入一张植物生病的照片,多模态聊天机器人能根据照片和用户输入的文本,给出植物生病原因和救治建议等综合性的回答,这是单模态聊天机器人无法做到的。
© 版权声明
本站文章版权归奇想AI导航网所有,未经允许禁止任何形式的转载。
相关文章


















奇想AI导航网收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,奇想AI导航网还推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务!
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。